
Gerencie o rápido crescimento dos volumes, variedade e velocidade dos dados com ferramentas visuais que reduzem o tempo e a complexidade de construção e manutenção de pipelines de dados analíticos.
Faça a ingestão de múltiplas fontes de dados para o seu Data Lake ou Datawarehouse, de maneira rápida e eficiente. Escolha a Engine de execução do seu Pipeline Analitico que melhor se adeque a sua necessidade, sem a alteração da sua regra de negócio.
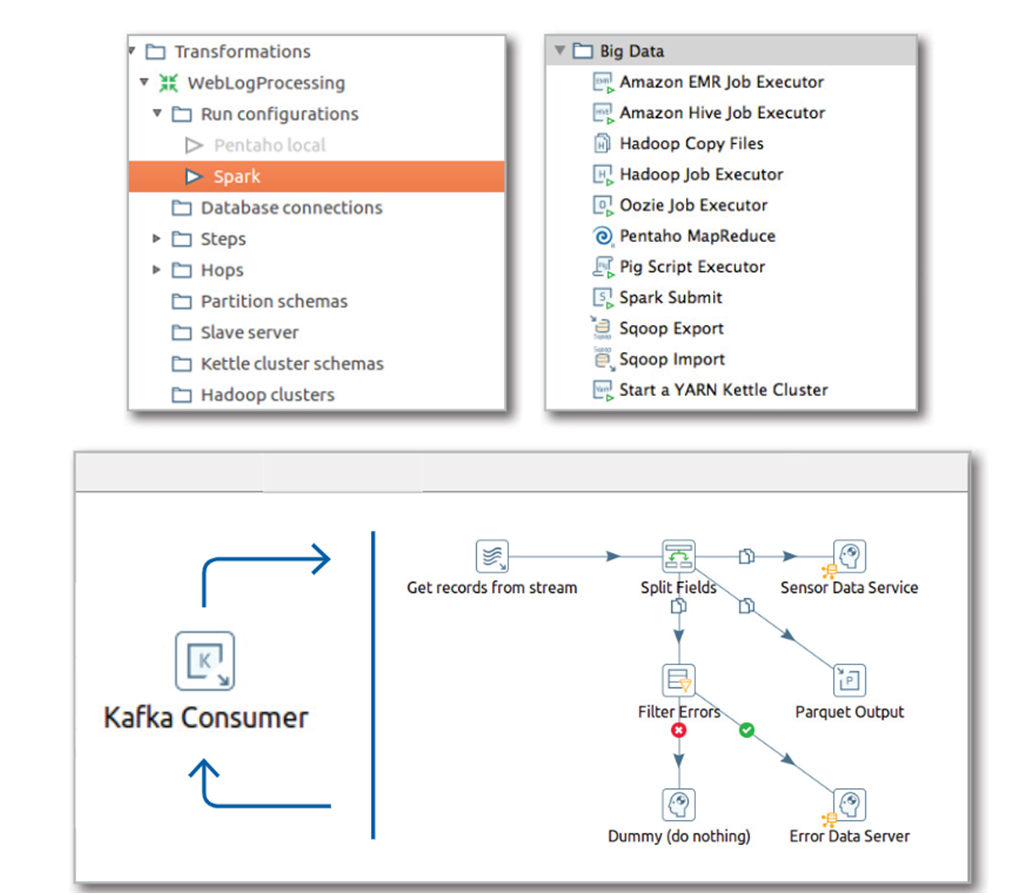
Crie, implante e monitore fluxos de dados de forma colaborativa para agilizar a entrega de dados.
- Integração de dados acelerada
- Ampla conectividade para praticamente qualquer fonte de dados ou aplicativo
- Interface de arrastar e soltar para criar pipelines de dados
- Modelos de fluxo de dados que executam do edge-to-cloud
- Autoatendimento de dados
- visualização de dados em linha e passo a passo
- Combine dados em qualquer lugar no local ou na nuvem
- Arquitetura flexível para rodar em qualquer lugar
- Orquestração robusta do Dataflow
- Alterne perfeitamente entre o motor nativo do Pentaho e o Apache Spark
- Operacionalize modelos de aprendizado de máquina R, Python, Scala e Weka
- Estenda para análise com integração embutida em Apps e Portais de Informação
Com Pentaho Data Integration (PDI), um produto LumadaDataOpsSuite, o gerenciamento de enormes volumes e aumento da variedade e velocidade de entrada de dados nas organizações é simplificado. O PDI fornece dados prontos para análise aos usuários finais mais rapidamente com ferramentas visuais que reduzem o tempo e a complexidade. Sem escrever SQL ou codificar em Java ou Python, as organizações imediatamente obtêm valor real de seus dados, de fontes como arquivos, bancos de dados relacionais, Hadoop e muito mais, que estão na nuvem ou no local.
Transforme o Big Data em análises acionáveis. A camada de big data adaptável da Pentaho permite que você se conecte a armazenamentos de big data populares com flexibilidade e isolamento contra mudanças. Os dados podem ser acessados uma vez, depois processados, combinados e consumidos em qualquer lugar. A camada de big data adaptável da Pentaho inclui plug-ins para distribuições Hadoop de Cloudera, Hortonworks, MapR, Amazon Web Services ElasticMapReduce (AWS EMR), Google Cloud e Microsoft AzureHDInsight, armazenamentos de objetos como Hitachi Content Platform, bem como bancos de dados NoSQL populares como MongoDB e Cassandra.
Contate-nos e veja como podemos te ajudar nesse processo!
